

.png)
A transformational technological advancement
Why are we still funding blockchain infrastructure in crypto?
The Bitcoin whitepaper, with proof of work as the solution to the double spend problem, was released more than fifteen years ago. The Ethereum whitepaper, which expanded the possibility set for applications by introducing a Turing-complete programming language for a blockchain, is a decade old.
And yet infrastructure funding and mindshare continues to dominate. Investors continue to put resources into base level infrastructure projects — L1s, L2s, the modular stack, account abstraction, intents. Almost all the top valued projects in the space are infrastructure projects, even when they seem to lack any meaningful number of users or applications.
Many people: founders, investors, regulators look at all this and ask the logical question: has anything been achieved here — what is the point of all this infrastructure investment, and are we closer to new applications?
To answer this question, we need to understand what blockchains solve: where they came from, what properties they have, and what are the trade-offs they inherently introduce to achieve them.

As we unpack below, blockchains are a transformational technological advancement — a technology without a defined use case. Such technological leaps are not common, but they have the potential to be utterly transformative.
No technological advancement is exactly alike, but we have historical precedent for the adoption cycle for such abstract solutions, and the heavy lifting and cumulative technological innovation required to facilitate even a rudimentary application layer. Part of the reason for this is the inherent constraints that such transformative technologies introduce — solvable constraints but constraints nonetheless that need to be overcome for application layer adoption.
There are three important points to make here:
- There are many iterative breakthroughs required to get from the initial technological advancement to end applications; this process requires not just time but also insight from varied associated technological fields
- These technologies ultimately become associated with multiple different application areas
- the rate of maturation of each new application area emerges at different speeds due to different tradeoffs in the underlying technology
To illustrate these points we consider two examples.
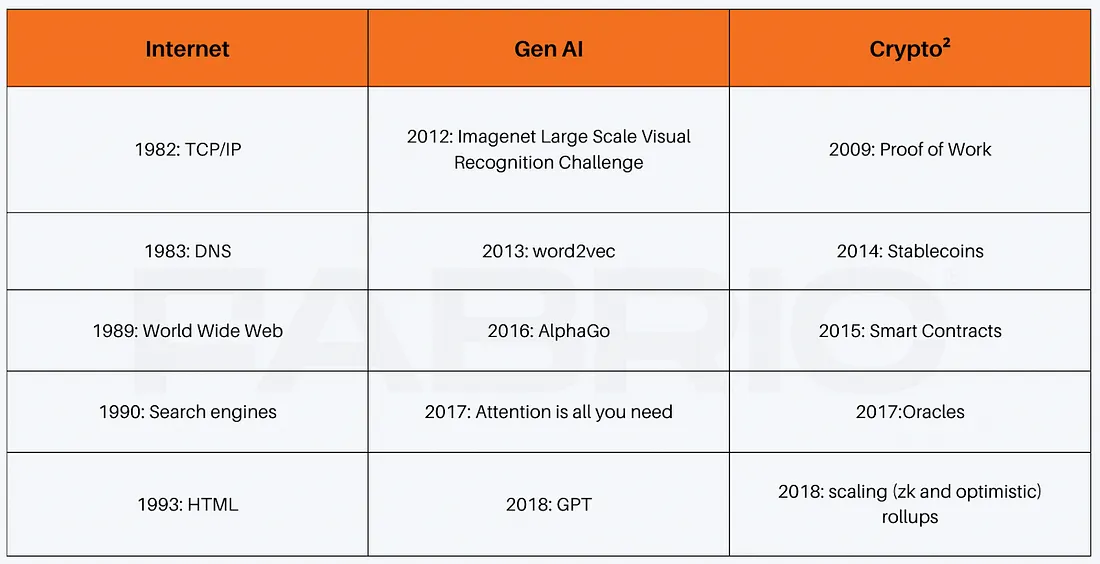
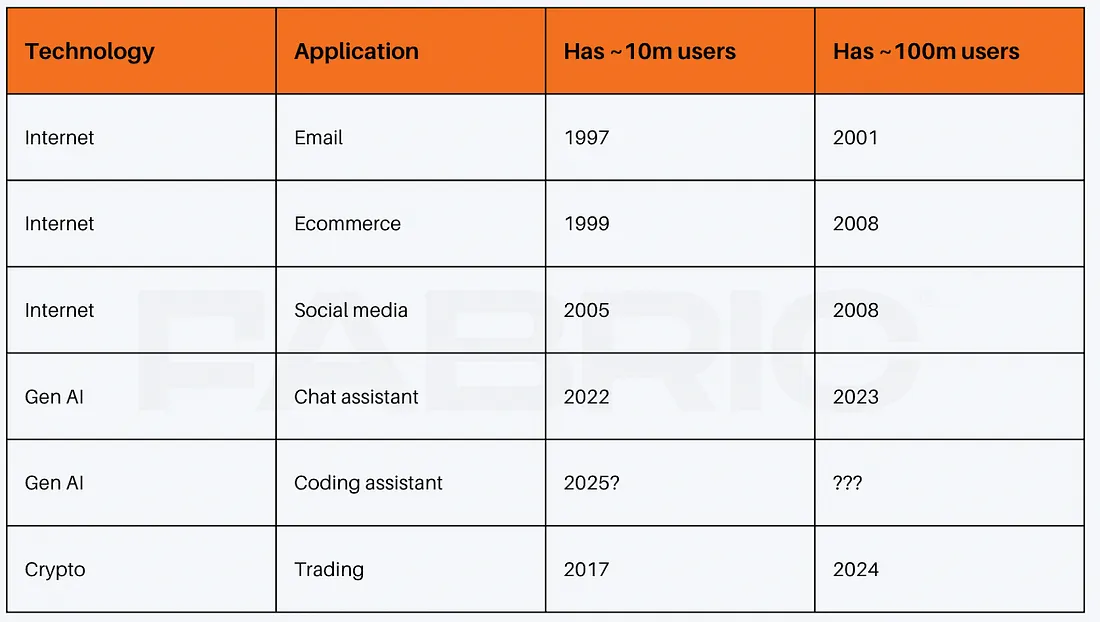
While the exact starting point is up for debate, it is plausible to argue that the internet was fundamentally set on its irrepressible path with TCP/IP in the early eighties. Even by that point in time, the first version of the applications that would later become popular already existed, with the first emails sent in the early 70s, the first ecommerce sites in the early 80s, and the first chatrooms in the late 80s. It took more than a decade of infrastructural innovation for these applications to hit the mainstream.
More recently AI has captured the imagination, displaying the potential of another transformational technological advancement. While for much of the world it seemed as if ChatGPT emerged perfectly formed in the autumn of 2022, it also was the result of decades of crucial infrastructural and academic innovation. Research in neural networks goes back to the 1950s, while contemporary innovation accelerated with Alexnet and the 2012 imagenet visual recognition challenge. The resulting decade saw important technical innovations without which it’s hard to imagine the applications of today, such as transformers (on which modern models are based) or AlphaGo (showing the power of reinforcement learning on which reasoning models such as o1 or deepseek’s r1 rely). The first mass consumer product that came from these breakthroughs wasn’t seen until ChatGPT (and has since accelerated with new applications such as coding assistants).
Crypto has similarly seen important iterative technical innovation. Beyond the important innovations of proof of work (Bitcoin) and a turning complete language for writing smart contracts (Ethereum), immense innovation has happened around scaling and privacy technologies such as data availability sampling, zero knowledge proofs, and homomorphic encryption.
Why do we need to spend so much time building infrastructure before we see applications?
The answer to this and what is so exciting about these sorts of innovations is that they possess at their core a set of desirable properties, which are potentially applicable to a whole range of use cases. However, they are blunt instruments. Different applications prioritize those properties to different degrees, and each vertical has its own existing set of incumbent solutions, that any application built on these novel technologies must ultimately outperform.
The Internet’s “impact on the economy has been no greater than the fax machine’s” Paul Krugman, 1995
This is why it is easy to dismiss these technologies when the trough of disillusionment sets in. Unlike other technological shifts (such as fintech or mobile, to use recent examples) the underlying technology is not designed with consumers and consumer applications in mind — instead those are revealed through trial and error and iterative improvement. Builders must understand which properties are relevant to their set of applications: emphasise those, and de-emphasise or cast off the properties which are less important.
Of course the ultimate promise for builders is greater still. Once applications built on a new technology are on par with the incumbents, the advantage conveyed by the properties inherent to the technology can truly shine, providing a competitive advantage. Furthermore, the scope of applications that can use the technology are not limited by any one use case; rather they can be deployed across a whole range of unconnected industries.
What are the properties of blockchains and why do we care?
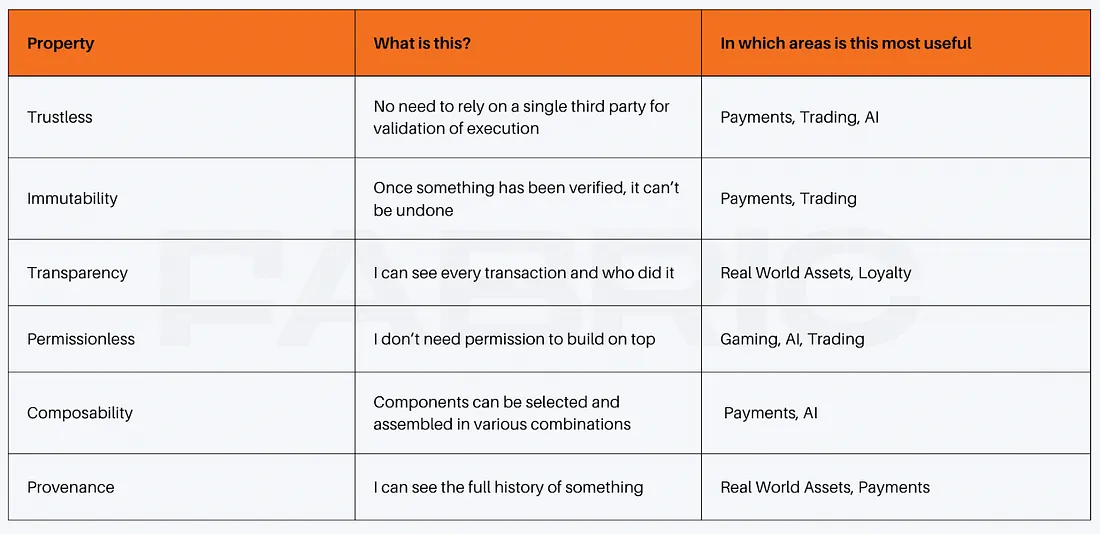
There are several important points to note here. The first is that these properties do not exist in a vacuum, nor do they come about painlessly or easily. There are very deliberate tradeoffs that are inherent to the technological choices that led to their emergence. As a result, their prioritisation leads to, almost by definition, a degradation of the user experience. The second is that not all of the above properties receive the same emphasis. Bitcoin and Ethereum, in particular, prioritise Trustlessness and Immutability almost above all else, with decentralisation a key requirement to guarantee that outcome. Guaranteeing Trustlessness and Immutability on a global scale is an astonishingly hard problem, compared to providing Transparency (which has been the basis of many web2 applications for decades).
Finally, and arguably most importantly, applications built on this new technology must require at least some of the above properties, in particular those properties which are hard to achieve without this infrastructure. Furthermore those properties need to be absolutely core to the function of the application — the reason users will be drawn to it. In absence of this, the application will effectively be a worse version of an application that can be built with existing infrastructure (This can be neatly summarised as the “why does this need to be on a blockchain?” question).
To illustrate where we have come, and where we should go next, we look at the history of crypto infrastructure through a lens of the properties that the key infrastructure projects of each era prioritised, and how this influenced the most appropriate application areas.
The history of crypto infrastructure
Phase 1: the cryptocurrency era: the tokens are the point
- Very Trustless, Very Immutable
It is no surprise that overtly financial applications dominated the space — Trustlessness, which allows for disintermediation of value extractive middlemen — and Immutability — once a transaction has been completed it is permanent and you no longer need to worry about its execution — are hugely valuable properties across the financial spectrum.
Bitcoin’s journey to product market fit as an alternative asset akin to gold has been something of a slow burn with gradual accumulation of mindshare and capital over the past 15 years. Its key properties (Trustlessness and Immutability), however, gave users comfort almost immediately to deposit significant funds allowing it to become a store of value, a crucial requirement for any currency. This is no mean feat. Historically users’ propensity to move funds from where it was safe (under the bed, banks, gold) to new mediums went hand in hand with defined regulation guaranteeing that those funds would remain secure. Bitcoin solved it in an elegant technological manner, showing the potency of those properties to the next generation of blockchains.
The other blockchains of this era were also overtly financially focused. Litecoin, Ripple, every project was aiming to be a currency or at the very least become a store of value, as Bitcoin had before them.
Phase 2: smart contract era: sell blockspace
- Very Composable, Very Permissionless, Mostly Trustless, Immutable
It is widely underappreciated the extent to which Ethereum found product market fit almost instantly. It maintained the Trustless and Immutable properties (with the same underlying mechanism as Bitcoin), making it highly relevant for overtly financial applications, but leaned into “Permissionlessness” and “Composibility” with a Turing complete, accessible language (Solidity). No longer did projects have to build their own blockchains to define their tokens (as had practically been the case previously), they could simply and easily launch an ERC-20 token and let Ethereum take care of the infrastructure (this was crucial for the ICO boom of 2017–2018 as launching any token became disproportionately easier). Permissionlessness and Composibility were also the driving properties for moving users off centralised exchanges and on-chain. Uniswap made it significantly easier for users to trade tokens before they were listed, Aave and dYdX gave users the ability to leverage their investments (through different mechanisms and with slightly different use cases) without conforming to the restrictions of prescribed leverage and liquidity available on the centralized exchanges. Composable systems meant conforming to pre-defined standards (such as ERC-20 or ERC-721) gave the long tail of assets easy access to existing infrastructure at launch.
The ‘Ethereum killers’ that followed (Polkadot, Near, Solana, Cosmos) saw the success of Ethereum and looked to solve the most pressing concerns that had arisen.
The biggest consumer pain point for interacting onchain swiftly became cost, specifically gas fees. The solution was to relax the “Trustless” property (albeit as little as possible), mostly by reducing the amount of distributed computational power required for an individual transaction’s consensus. There were two primary ways to accomplish this:
- Increase the block size reducing the amount of consensus required per transaction. This decreases the accessibility of block production to potential participants
- Reduce the computation redundancy per transaction. There are a few ways to accomplish this, but all have some concept of “division of work” where a subset of nodes verify a portion of the transactions with sufficient redundancy to guarantee liveness.
Blockchains in this phase had different technical architectures (Sharding, parallelisation, etc) but the same core goal. More transactions per second, lower latency, cheaper transactions. There was also an implicit belief that Composability was critical. Inspired by Ethereum’s success as a monolithic blockchain, the liquidity it had attracted, as well as DeFi’s unique features such as flash loans, (or perhaps more cynically as a belief around value accrual), the main players of this era looked to control the full stack of blockchain infrastructure on a singular chain.
With demand and mindshare coming to the space, there was also a concerted effort to improve the developer experience by allowing them to either use existing coding languages or formats in which they were already comfortable (Rust, JavaScript) or new languages that were specifically designed to be appropriate for blockchains (o1js, Move).
This was more evolution than revolution; the properties that users cared about were not meaningfully expanded or reprioritised, and so it should be of no surprise that the use cases that attracted lasting traction remained the same as those pioneered by Ethereum — launching or trading tokens.
Phase 3: modular components: unlimited cheap, available, flexible scalable blockspace
- Very Permissionless, customisable Trustlessness, mostly Immutable, somewhat Composable
The current phase of infrastructure has both continued to push the boundaries of scalability (i.e. reduced cost and latency) while both minimising the loss of Trustlessness as well as designing systems for customisable Trustlessness. The core driver of scalability was again reducing the computation overhead per transaction. Most of the innovation in this period has focused on two areas:
- ZK or optimistic settlement — aggregation of transactions and performing consensus over the aggregation rather than the individual transactions.
- Modularisation — separate the activities of consensus into the different tasks and provide specialised layers for each task, with flexibility for customisation.
This led to the rise of L2s (such as Optimism, Zksync, Base), modular blockchains (Celestia, Avail) as well as key service providers (the entire zk stack such as Risc0/Succinct, or rollup as a service players such as Caldera) who enable anyone to launch their own blockchain with little infrastructural overhead. More recently teams such as Rialo have looked to define the customisability of compute for consensus for different activities (such as oracles or bridges) at the very heart of the protocol.
Additionally a separate branch of infrastructure has focused on customising the Trustless property, such that applications can decide what level of Trustlessness is appropriate for their application.
Bittensor and Eigenlayer both fall into this category; allowing each subnet/AVS to define their criteria for consensus success (either in terms of the amount of consensus required for classic blockchain state consensus in the case of Eigenlayer, or the definition of success itself in the case of Bittensor). At the same time both remove much of the Composibility property as individual subnets/AVS’s have no inherent interaction with or understanding of each other.
What comes next? What is Phase 4?
It seems to me we have reached the endgame for the “generic” Ethereum-like blockchain. Not only is the infrastructure for launching and trading tokens to permanently exist on a ledger pretty mature, but the type of user who wants to trade these sorts of tokens are already here. To phrase it a different way, we have saturated the application space for those who want pretty Trustless, pretty Immutable, Transparent, Provananced, and somewhat Composable properties for their applications.
It is also true that building a blockchain is easier than it has ever been. There are many different scaling solutions, developer tools, and execution environments to tailor a blockchain in new and different directions.
Phase 4: build a different type of blockchain for a different application space
- Relax different constraints — in particular Transparency, Provenance, and Immutability,
Blockchain builders need to prioritise properties that significantly appeal to new types of applications and be prepared to make the user experience worse for existing, trading-focused applications.
Crucially, infrastructure providers in these areas should be much more purposeful and technologically opinionated; explicitly building for specific use cases vs the “build it and they will come” approach that has hitherto dominated the space.
We are already seeing the green shoots of infrastructure in these domains; below we consider the likely next wave application spaces where more tailored infrastructure can thrive.